Heron#
Heronは、複数の画像/動画モデルと言語モデルをシームレスに統合するライブラリです。日本語のVision and Language (V&L)モデルをサポートしており、さらに様々なデータセットで学習された事前学習済みウェイトも提供します。
異なるLLMで構築されたマルチモーダルのデモページはこちらをご覧ください。(ともに日本語対応)

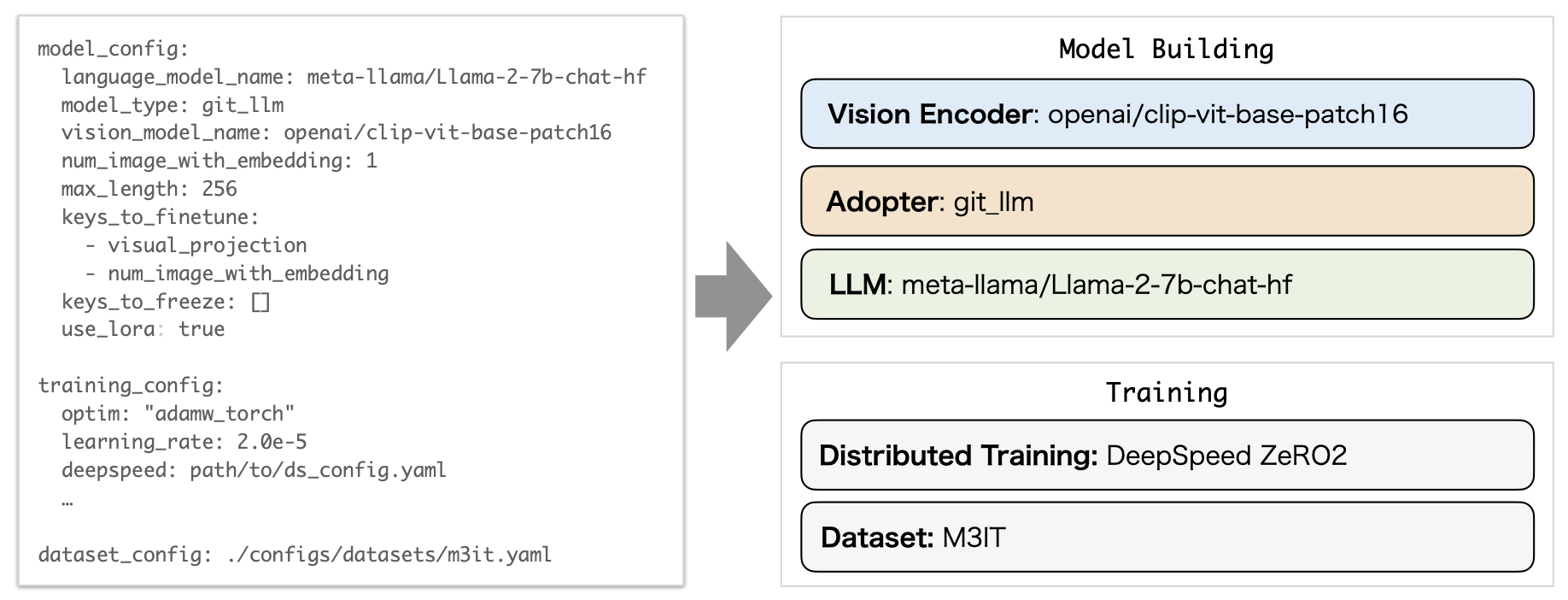
Heronでは、様々なモジュールを組み合わせた独自のV&Lモデルを構成することができます。Vision Encoder、Adopter、LLMを設定ファイルで設定できます。分散学習方法やトレーニングに使用するデータセットも簡単に設定できます。
組織情報#
ライセンス#
Apache License 2.0において公開されています。
参考情報#
GenerativeImage2Text: モデルの構成方法の着想はGITに基づいています。
Llava : 本ライブラリはLlavaプロジェクトを参考にしています。
Contents